
Is Eval by Time enough to determine Elo?
No and whyBefore reading this post
The games in this analysis were lichess-annotated 1+0 bullet games from July 2023. More about the data can be found at the lichess open database. The study was conducted on games that were 1+0 without berserk or any time odds. I will use the term elo for rating since the lichess database notates it as elo in their database. The code can be accessed here.
Short description of the dataset
The dataset was generated with 66 columns. 5 columns were player (replaced with ID numbers in the sample), player_color (1 for white -1 for black), player_result (1 for win, -1 for loss, 0 for draw), and player and opponent elo. All the other 0 - 60 columns were the latest evaluation from the player's time. For instance, if they made moves 1, 2, and 3 in 0 seconds it would record the evaluation at move 3.
When checkmate happened before a certain time, the following values were replaced with max+1 and min-1 of evaluation (201, and -201).
The following would be a sample graph of eval by time. The evaluation was recorded at each time of the game. Black checkmated white when the player had 40ish seconds left. After that, the values were replaced with the minimum value of the dataset.
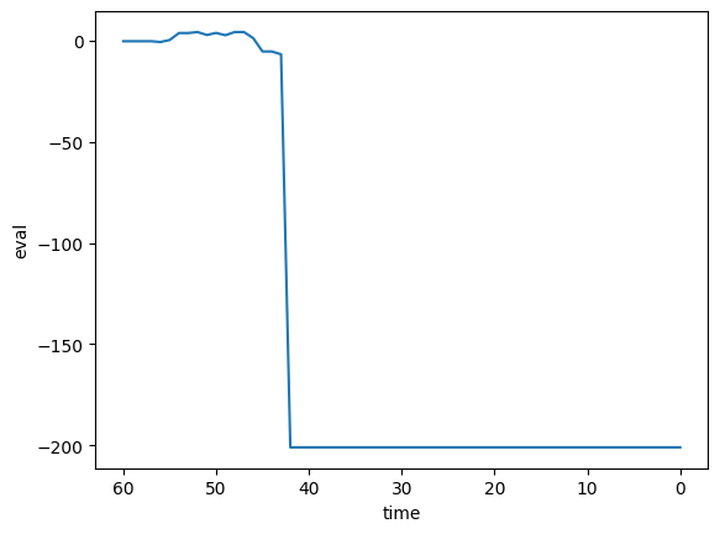
Generating a dataset with only Evaluation and Time
For my original experiment, I decided to give the models 4 information: Opponent elo, player color, game result, and evaluation time series of the player. The Time Series regressor did a great job of predicting the player's elo.
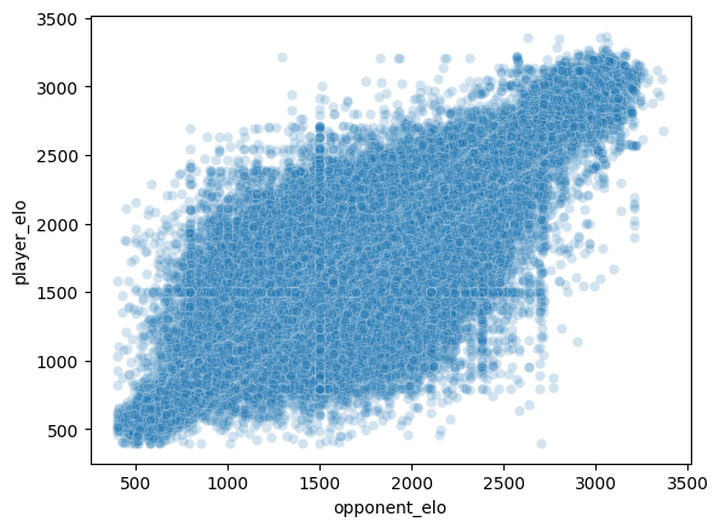
However, the models seemed to significantly rely on the opponent elo information. The training set had the following distribution of opponent_elo and player_elo. There is a trend of player_elo and opponent_elo being similar due to matchmaking but there were cases of elo difference being large which was completely neglected by the ML model (This may be due to the squared error loss).
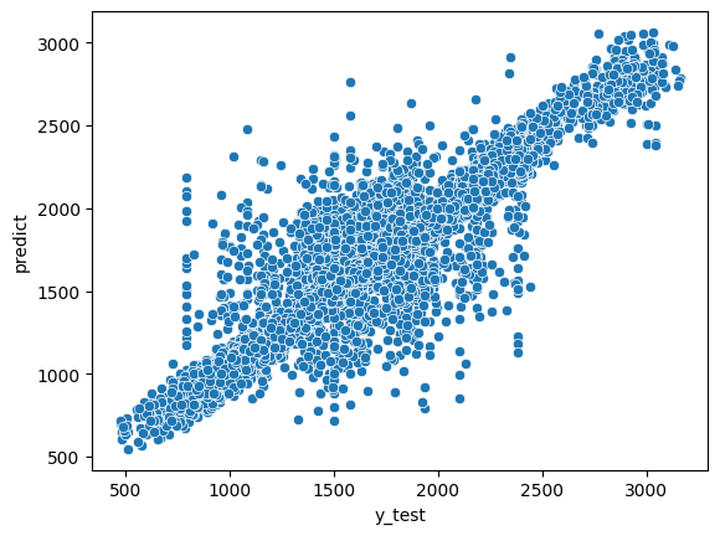
The following were the predictions made from ML models. We can see that they just use the information they were given.
This didn't seem like an ideal ML model that analyzes the information correctly.
Without opponent elo information
The results from my original experiment led me to expand the experiment. I decided to train models solely on eval by time and make the models predict the elos of players. The ability to properly determine the average elo and the difference of elo in each game means it can identify the elo of two players precisely. However, most ML models I trained failed miserably on this task. You can check the different models I made on github. I will show some sample results on guessing average elo and elo_difference.
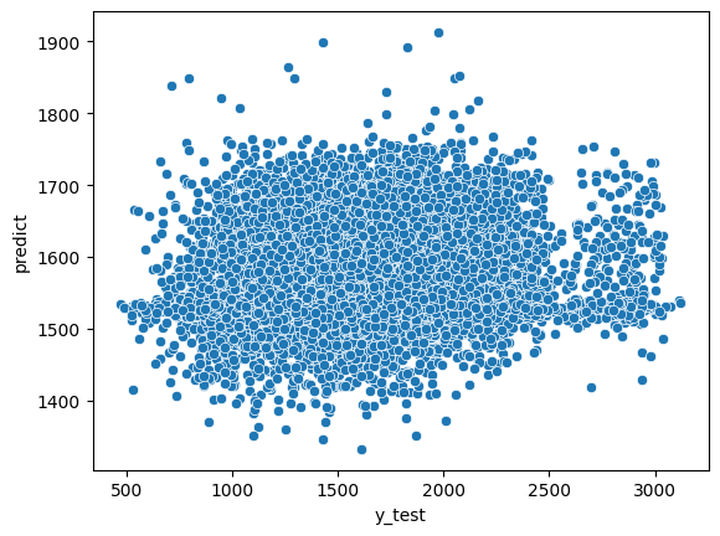
This was a TimeSeriesMLPRegressor for guessing average elo. y_test is the true value. predict is the predicted value by the ML model. We see they can't relate the data well.
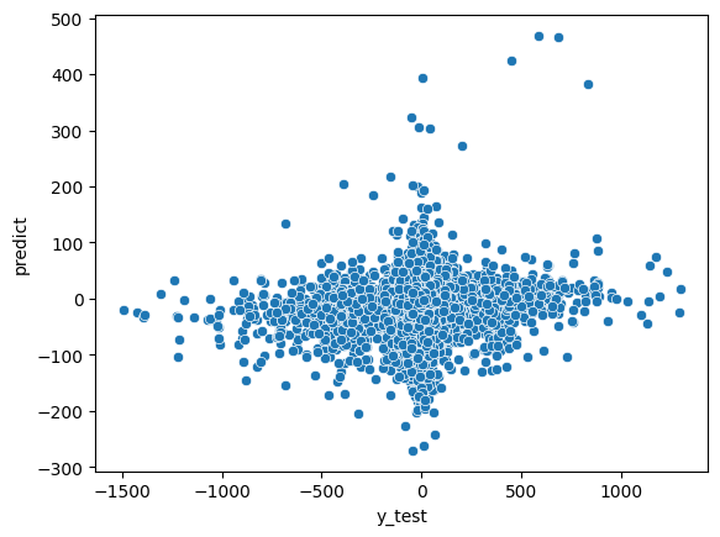
This was a random forest regressor on elo difference.
Conclusion and limitations
The short answer is No. Evaluation by Time was not enough to determine the elo or elo difference between players. From this format of the dataset, the models were not able to find the trend of average elo or elo difference between players just by looking at the changes of evaluation over time. This may be caused by several reasons. Mostly the dataset itself might cause the problems.
- The sense of move number is not reflected in the dataset.
- The dataset cannot differentiate blundering move 1 at 60 seconds into -5 evaluation and blundering move 30 at 60 seconds into -5 evaluation.
- Replacing values with max+1 and min-1 of evaluation with min max scaler could have made the ML model have harder time catching good signals.
- The dataset was not recreated for elo and elo difference purposes.
- The dataset is centered around one player's time and evaluation which may be insufficient information to determine the average elo or the difference of elo between players.
- However, it is hard to collect both players' time into one time series. This might be solved by feeding both time series to the model.
- A better selection of loss functions might solve the problem.
- Maybe there is a very low correlation between evaluation by time and elo, or elo difference.
- This seems less likely but is the current conclusion.
It may be very obvious that evaluation by time on one player is not enough information to guess the elo of the player. Such questions might sound absurd but I wanted to test them myself. Not all experiments are successful. Probably this dataset generation and testing (which took more than 20 hours of code execution) is closer to a failure due to wrong planning with lots of limitations. I wanted to share the process I go through. I will return with longer and better-made studies. If you have ideas about improving this I would love to hear.
More blog posts by oortcloud_o

Linking top players based on openings
Using relatedness network on opening choices of top grandmasters
Which openings are related?
simulating opening connectivity graphs with known techniques
A short literature review
chess opening similarity and more